Report: Stock Analysis with Neural Networks
I worked with stock data because I thought it would be interesting to use machine learning techniques with data that is already primarily in a numerical format. I was inspired by youtubers who used advanced machine learning techniques and automated trading to make money from currencies in video games, crypto currencies, and foreign currency exchanges.
Data Prepossessing
This project uses data collected from Yahoo Finance about Alphabet (GOOG) stock from August 1st of 2004 (08/01/2004), when the company was founded, until July 10th of 2019 (07/10/2019). I only used information provided by the free version of Yahoo Finance. Yahoo Finance provides data in a comma-separated value file (“.csv” extension). I manually separated data into testing and training sets. I did so because late into the project it became clear that using all previous-day-information to predict the next day was over-fitting. Dr. Clark advised that I should some number n where only the n preceding day’s value is used to predict the next day’s value. This number of days led to a lot of time being spent on re-splitting the data because the number of days it should see before were modified. Getting the data into the program was easy with PANDAS. PANDAS is a great library with a built-in converter from CSV files to a PANDAS DataFrame data type. From these DataFrames it is much easier to access and manipulate columns and rows. Once the data had been converted, I used Sci-Kit learn pre-process data using min-max scaling.
Version Control
Because the data was such a pain to split up, I tried to change the number of previous inputs as few times as possible. One tool that allowed me to work on the same data at home and while I was working an office job was Git. The computers at my work were locked down, and I could not use IPython or Jupyter but I could use Git for windows. After a few times cloning, branching, committing and pulling it gets easier. This technology helped a lot and assured that I always had access to my most up-to-date code.
Building the Model with Keras
I wanted to work with TensorFlow but found the library was too cumbersome and technical. I stumbled across Keras which is a popular data science library that has been written on top of TensorFlow. The power of this library is that it includes simple and concise APIs that reflect what is happening at a logical or abstract level. Any errors that Keras comes across are easily debuggable because Keras has helpful error messages, sometimes even recommending changes. Once I completed a simple regression model based only on one data feature (for 15 days) and was satisfied with my results, adding another set of features or adding a layer can typically be accomplished in less than 5 lines of code. Keras managing so much information allowed me to really focus on getting a working model. The model I built took 15 previous days stock opening price and used this to predict the next closing price. Predicting what the market should close at for the current day.
Results
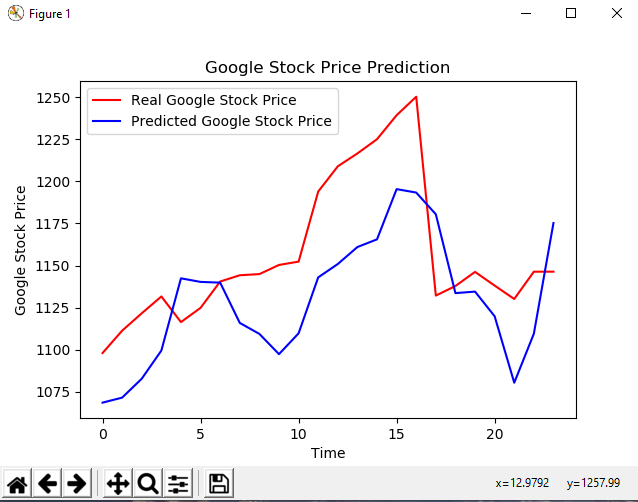
Training for 15 days to predict the next day using only one layer, which is a simple regression model, yielded accuracy around 70 to 90 percent. One thing that still confuses me is that the number of Epochs, or number of times the model is trained, had no impact on the accuracy. I played with adding layers to the model to make it a neural network but the improvements were trivial. The only thing that I found that gave me consistently better results was using the Adam optimization technique, described in this paper instead of the Stochastic Gradient Descent optimization approach. I would be lying if I said I really understood the difference between the two but I wanted to play with how the model was being optimized to see what results I could get. After researching it appears that maybe this technique is more computationally taxing, and that is why it provides better results.
What I Learned
When I started this course, I thought I knew a lot more than I did. I thought I could improvise around what I did not fully understand using libraries as a crutch. In my head I wanted to defeat this view, but I found that my progress at first was slow. I had to figure out a model to use and fix the data to my liking. Both tasks took serious amounts of time. When I first started looking at TensorFlow documentation, I was completely lost. I thought maybe PyTorch would be a good alternative but after looking at many alternatives I gave one called Keras a try. After the project looking back my outlook seems naïve. AI/machine Learning is already so complicated that people build these tools to make others’ lives easier when they want to use these techniques to solve a problem. This sounds obvious but I think this has really changed my viewpoint as a programmer. I think I would like to contribute to an open source project that I use. Here is a link to the code for this project.